Monte Carlo Guide
What and why
Monte Carlo (MC) is our Data Observability tool and helps us deliver better results more efficiently.
The Data Team default for observing the status of the data is using Monte Carlo. Creating any tests (called monitors in MonteCarlo) are done via the UI of Monte Carlo and reported according to the notification strategy. On another iteration in the near future we plan to implement Monitors as Code and these tests will also be version controlled. Currently dbt still used for existing tests, there is no roadmap in place to migrate these to Monte Carlo.
Current State and Use Cases of Monte Carlo
Number of Users:30Number of systems:1 (Snowflake)Number of tables:7,000+ tablesTables under active Alert:1,700+ tables- Part of Daily Data Triage
- Create Custom Monitors for advanced use cases
- Pilot Monitoring Tool for select dbt tests
Future Plans for Monte Carlo
- Deploy as SSOT Monitoring Tool for Analytics Engineering (within the dimensional model layer)
- Trusted Data Monitoring - migrate dbt Trusted Data tests into Monte Carlo and deprecate these tests
- Monitors as Code - add monitors to Denomas for version control
- (Stretch) Automated Denomas Issue Generation on MC incident generation
How We Operate Monte Carlo
We use the #data-pipelines Slack channel for MC platform related alerts. We are planning on using the #data-analytics Slack channel in the near future for model related alerts, as soon as we have implemented the full notification strategy for Monte Carlo. This work is planned under this epic for F23Q3: Onboard Analytics Engineers to the Monte Carlo Tool
Monte Carlo is an integral part of our Daily Data Triage and will replace the TD Trusted Data Dashboards.
graph TD mc(Monte Carlo) sf(Snowflake Data Warehouse) de(Denomas Team Member) mc --> |alerts| de de --> |improves| sf sf --> |observes|mc
The whole body of work covering the Monte Carlo rollout at Denomas falls under epic Rollout Data Observability Tool with 100% coverage of Tier 1 Tables to improve Trusted Data, Data Quality, and Data Team member efficiency, where the work breakdown has been done and issues have been created to reflect the necessary steps until we are up and running with Monte Carlo on production.
Logging In
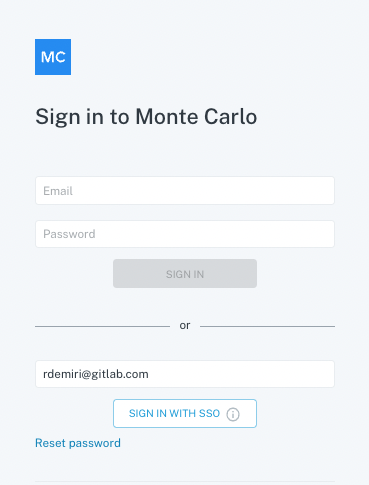
Login to Monte Carlo is done via Okta. Go to https://getmontecarlo.com/signin. The following screen appears upon login and after providing your email and clicking “Sign in with SSO”, you should be redirected to your Okta login. Please note, you need to login via SSO and not via username/password.
A runbook of how everything is technically set up can be found in the Monte Carlo Runbook.
The gist of it is that there is an Okta Group called okta-montecarlo-users that is maintained by the Data team and has the Monte Carlo app assigned to it.
In order to be able to access Monte Carlo via Okta by default, your user should be part of the okta-montecarlo-users group.
For that you should submit an AR (similar ARs: [Example AR 1]](https://code.denomas.com/denomas-com/team-member-epics/access-requests/-/issues/22860), Example AR 2) and assign it to Rigerta Demiri (@rigerta) or ping the #data channel linking the AR.
Navigating the UI
Once logged in, you should be able to see the Monte Carlo Monitors dashboard with details on the objects being monitored and several custom monitors that have already been set up.
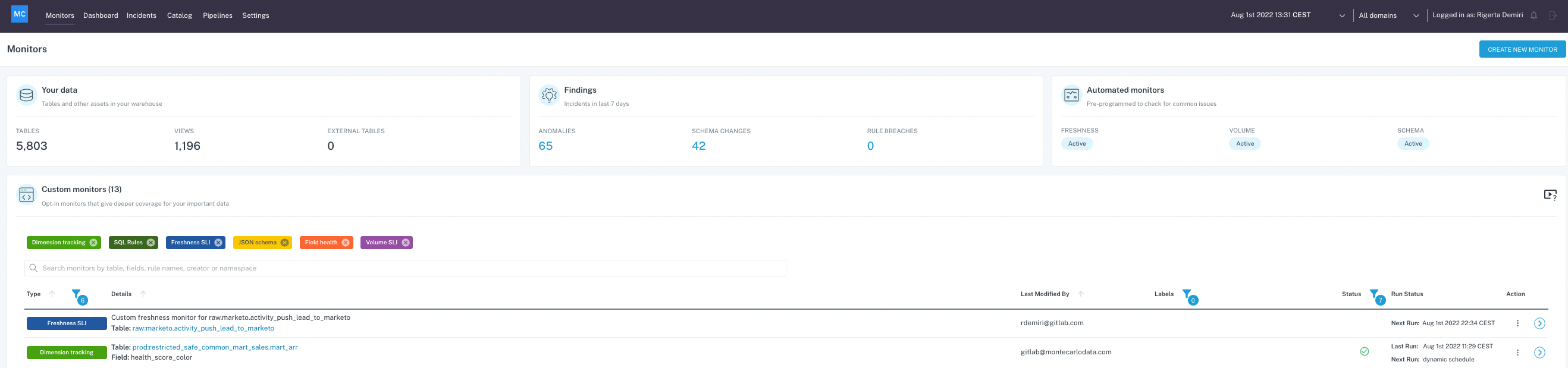
You can create a new monitor or view existing monitor details, such as definition and schedule and any anomalies related to it. Alternatively, you can also list all the incidents by clicking on the Incidents menu item on the top menu bar, you can search for a specific model by querying the Catalog view or check Pipelines for a detailed lineage information on how the data flows from the source to the production model.
Depending on the role assigned to your user (by default every user logging in via SSO is assigned a Viewer role), you might be able to see Settings and check existing users and integrations (such as Slack integration, Snowflake integration, dbt integration etc.)
If you need your role to be updated, you can reach out to anyone on the data platform team and they will be able to modify your existing role.
More information on navigating the UI can be found in the official Monte Carlo documentation.
Adding a New Monitor
Monte Carlo will be running volume, freshness and schema change monitors by default on all the objects it has access to. However, these checks are based on update patterns the tool learns from the data and if you need a specific custom check that runs on a certain schedule, you might want to add a custom monitor for that.
The official Monte Carlo documentation on monitors can be found in the Monitors Overview guide.
Fine-Tuning an Existing Monitor
If you want to modify an existing monitor, depending on the type of monitor, you can modify different parts of it such as the schedule, the timestamp field to be taken into account & the alert condition.
Responding To A Slack Alert
Currently, when we are getting notifications on different Slack channels, we can already triage the issue via Slack by assigning a status to it choosing from: Fixed, Expected, Investigating, No action needed and False positive (No status is a default status by MonteCarlo).
Once we start investigating and we have a finding, if we write a comment on Slack in the same notification thread, that comment will automatically be added to the incident on Monte Carlo.
Our goal is to be able to integrate Monte Carlo with Denomas so that whenever we get an alert on Slack, a triage issue would automatically be opened on Denomas and we’d follow the same Data Triage procedure as usual.
There is detailed information including a video section in the official Monte Carlo documentation on how to respond to an alert.
Incident status
Each MonteCarlo incident has always a status. See the folowwing list when to use which status:
| MonteCarlo status | Context | Actions done or to -do |
|---|---|---|
| Fixed | Incident is not active anymore. | Actively worked on resolving the incident or the incident is normalized automatically. |
| Expected | Incident was flagged by MonteCarlo correctly. We knew that this was coming, like a batch update or a schema change that was in the works. | None |
| Investigating | Actively working on the incident | Root cause investigation and resolve if needed |
| No action needed | Incident was flagged by MonteCarlo correctly, but its not a breaking change | None |
| False positive | Incident was flagged by MonteCarlo wrongly | None |
| No Status | Default status by MonteCarlo | Start investigating and update status |
Note on DWH Permissions
In order for Monte Carlo to be integrated with Snowflake, we have had to run the permissions script as specified in the official docs for each database we needed to monitor.
The same script has to be run as many times as we have databases to monitor (in our case raw, prep and prod) with the correct values for the $database_to_monitor variable. The scrips foresees new tables to be added to existing schemas. In case of a new schema the script has to be executed again for the database the schema resides. The data observability user is stored on our internal data vault.
Please note this is an exception to our usual permission-handling procedure, where we rely on Permifrost, because observability permissions are an edge-case for Permifrost and not yet supported by the tool. There is an ongoing feature request on Permifrost for adding granularity to the way permissions are set, but no solution has been agreed on yet.
Notification strategy
All incidents are reported in MonteCarlo incident portal. For triage purposes the most important (which requires action) are routed towards Slack. The following matrix shows per data area which type of monitors are routed and towards which channel:
| Database | DataScope | Volume | Freshness | Schema changes | Custom monitors |
|---|---|---|---|---|---|
| RAW | TIER1 | #data-pipelines | #data-pipelines | #analytics-pipelines (once per day) | #data-pipelines |
| TIER2 | #data-pipelines | #data-pipelines | #analytics-pipelines (once per day) | #data-pipelines | |
| TIER3 | #data-pipelines | #data-pipelines | #analytics-pipelines (once per day) | #data-pipelines | |
| PREP | n/a | - | - | - | - |
| PROD | COMMON * |
#analytics-pipelines | #analytics-pipelines | - | #analytics-pipelines |
WORKSPACE ** |
- | - | - | - | |
| WORKSPACE-DATA-SCIENCE | #data-science-pipelines | #data-science-pipelines | - | #data-science-pipelines | |
LEGACY *** |
- | - | - | - |
* COMMON is also the COMMON_RESTRICTED equivalent. It excludes COMMON_PREP and COMMON_MAPPING
** WORKSPACE-DATA-SCIENCE is the only workspace schema we are including in the notification strategy
*** Only these two models (snowplow_structured_events_400 and snowplow_structured_events_all) of the LEGACY schema have been included temporarily as per !7049
Domains
We have the availability to use domains in our Monte Carlo environment. Currently domains can be used to create separate environments for separate team members, domains automatically filter monitors and incidents by projects and datasets. We have a limited number of domains available.
| Domain | Description | Data Scope |
|---|---|---|
| Data Platform Team | Domain for the Data Platform Team - scope raw data layer in Snowflake | Snowflake raw layer |
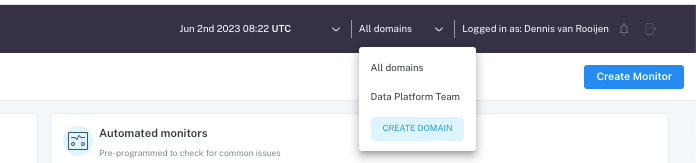
Use domains
In Monte Carlo UI in the top right corner there is a dropdown box available which you can select a particular domain or all domains.
3d741be9)
